Recently, I read an article from the folks at Public Knowledge titled “Application of the “Diversity Principle” in Content Moderation”. As with all their takes on content approaches, I found it to be a thoughtful consideration of an ideal, backed by a solid examination of the history of our media regulation efforts, and I applaud the thoughtful consideration of how to move forward in a world where our media lives are increasingly ruled by centralized platforms and recommendations algorithms. I believe that it makes a set of recommendations for editorial intent that seem like the right direction to move, but are likely difficult, if not impossible, to implement in practice.
The article identifies a basic problem of the algorithmic systems driving our media consumption being the resulting filter bubbles, or more directly, the shift towards extremism that these algorithms tend to create and then reinforce. In the linked New York Times op-ed from last year, Zeynep Tufekci called out this tendency towards radicalization as the fundamental issue of YouTube’s recommendations system: “It seems as if you are never “hard core” enough for YouTube’s recommendation algorithm. It promotes, recommends and disseminates videos in a manner that appears to constantly up the stakes.” The recommended course correction from Public Knowledge is to diversify: ie, if you imagine the bell curve of “level of radicalism” where the user’s current interest is centered, to expose a user of the platform to content on both sides of that curve, rather than only leaning in one direction.
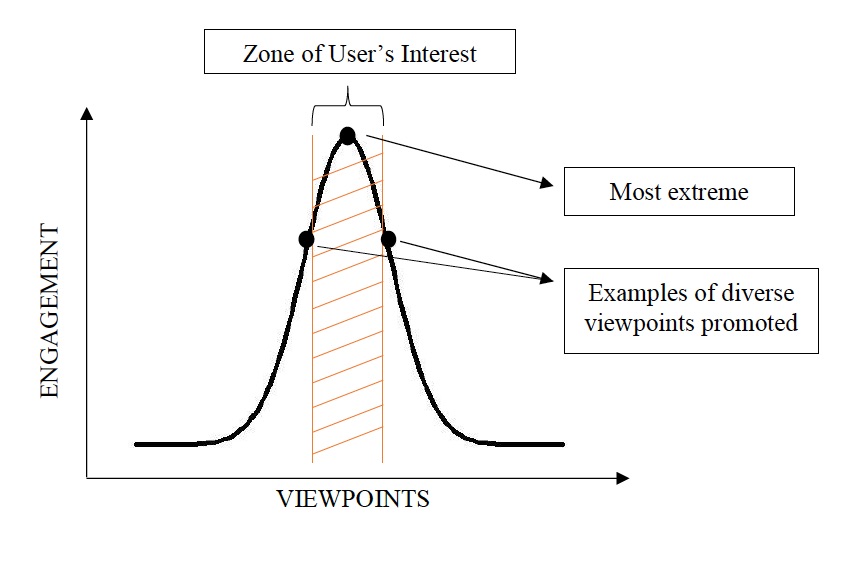 Visualization provided by the Public Knowledge post.
Visualization provided by the Public Knowledge post.
This may be possible – indeed, it may be necessary even if it is not possible today, in order to prevent YouTube, Facebook, and other major media platforms from continuing their role as our modern day radicalization engines. With the current technology and information available, however, I’m not sure whether it can be achieved. These break down into a number of core areas from my perspective: content identification, human behavior, and the unfortunate realities of the socio-political landscape.
Content Identification
Fundamentally, it seems that the recommended approach tends to see content as classifiable on a spectrum of less extreme to more extreme. As described by Public Knowledge: “By feeding in content that is similar to the sensationalized content but is less violent or politicized, and still within the zone of the user’s interest, we would be dispersing the attention that is given to the most extreme content.”
The issue with this is that I do not believe that platforms have any meaningful sense of how extreme content is. Facebook made the case in their Blueprint for Content Governance that content which is close to the limits of their policies on acceptable content saw more engagement, and they were working to shift users away from the edges of their policy boundaries.
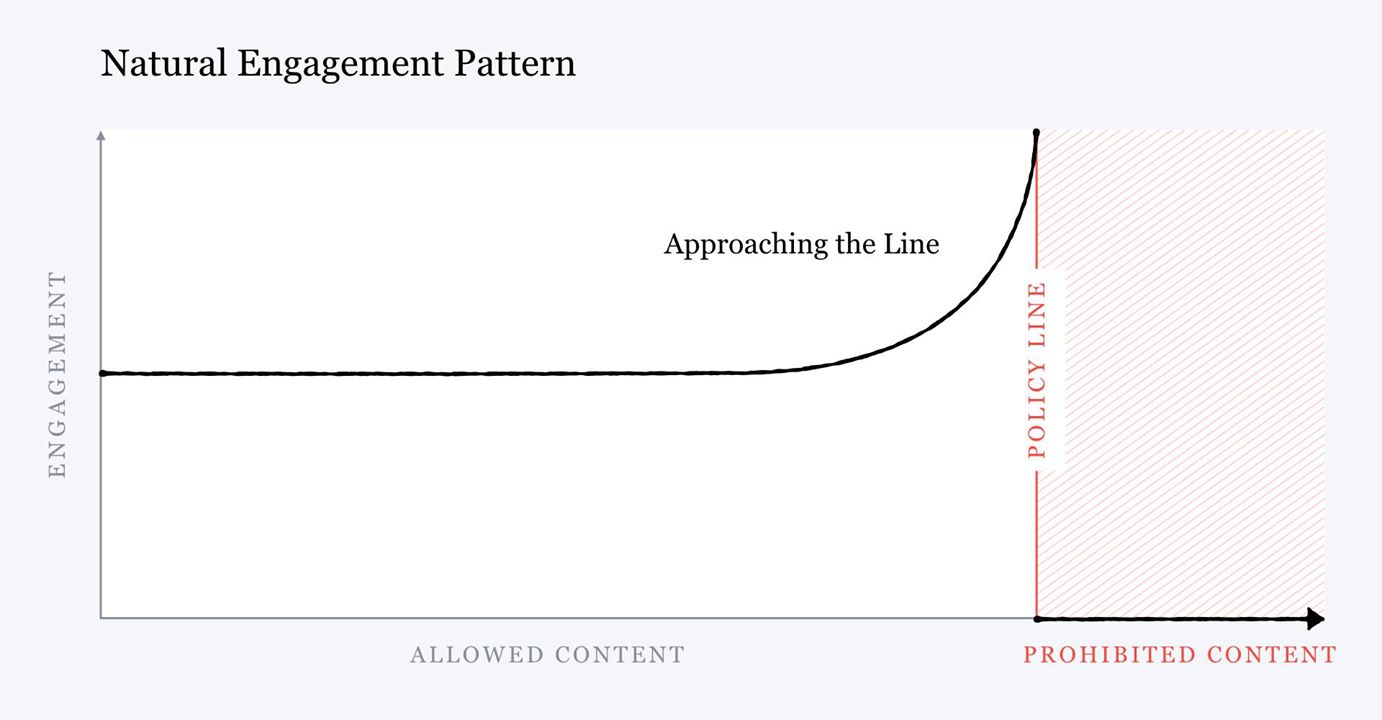
The issue I see is that I don’t believe this same tendency applies across the spectrum when you are far from some specific cut-off point. Their mocked up chart shows that there’s a broad range of content which is in the “allowed content” where measured engagement isn’t significantly affected by its proximity to the policy line. Only when content is close to some policy line does the engagement metric increase (and then dramatically increase).
When classifying a content towards a boolean value – “Is this a violation of policy or not?” – algorithms will often produce a prediction in the form of some kind of probability. “This content has a 99.8% probability of being violent”; “This content is 73% likely to be violating the policy around nudity.” With those specific policy evaluations in mind, there is certainly a range that platforms can use to order their content: The existence of a “porn classifier” indicates that there is a “least pornographic image” out there somewhere. (At least one internet user has mused that it’s probably an image of Ted Cruz.) In other words: what creates the ordering of content is specifically the existence of the policy line in the first place.
Absent specifically crafted boundaries with massive investments in labeled training data, however, it’s not clear that there is some generic “extremeness” classifier that can be used to order content. In the end, the existing classification systems that Facebook is describing in its post are not being measured or affected by how extreme they are, but rather “how close are they to an explicitly editorially crafted boundary created by content policy.”
To take the example of veganism from Ms. Tufekci: no website likely has the ability to classify food content on the scale between “extreme carnivore” through the typical middle of “run of the mill omnivore”, through the various classifications of pescetarian, vegetarian, and vegan. While building such a classifier would likely be possible – ordered labelling of food content based on how much it pushes towards some specific niche of food consumption – it seems unlikely that such a model would generalize to much of an extent with the same type of model classifying “intensity of sporting activity” from “jogging” to “ultramarathons”. There is no practical way to build an order for every piece of content from “least extreme” to “most extreme” without this kind of ordered training on every axis.
The reality is that content identification and classification systems, in my experience, are simply not very smart. The distinctions that people viewing content see as obvious in this way are something that it is difficult for me to imagine training, because most of these things are not explicit characteristics on which folks would agree, but rather a case of the classic principle of “you know it when you see it.”
Historically, of course, content differentiation and ordering has been crafted by editorial choices. Individual cable networks have a tendency to sort themselves from the least extreme type of content to more extreme on at least one axis: the range between PBS, Home and Garden TV, Comedy Central, Showtime, and HBO is broad, but described that way, most folks would likely be able to imagine at least one axis these networks differentiate themselves along a scale. (Even with this strong segmentation of the market, there’s no longer a really obvious categorization along the ‘extreme’ axis: channels like Home and Garden which have historically offered more serene content have now expanded into creating more extreme content, with items like the HGTV announcement just this morning that “The most extreme renovation show of all time is returning to TV”.) In any platform which exerts a strong editorial voice applied with influence of trained professionals, there is room to classify content along this spectrum, and if the content was so classified, use that spectrum to give consumers influence in one direction or another. But without that editorial influence, it’s difficult for me to see how to achieve the distribution of content along the described curve.
None of this is to indicate that I think platforms can abdicate this responsibility: I believe the recommendations of Public Knowledge to ensure that consumers are exposed to a range of content around their current viewpoint in both directions along an imagined extremism axis is an extremely useful tool. It’s clear that some of the tendencies that people recommend more broadly – for example, exposing viewers of questionable content directly to rebuttals of that content – would work significantly less well. I appreciate the intent; I simply can’t imagine how to implement it in a system where the dimensions of radicalization are likely so difficult to convert into the prescribed spectrum without a strong editorial voice on any more than a small number of explicit axes that would do little to combat the widespread problems with radicalization of consumption.
Human Behavior
Beyond the technical limitations, human behavior itself has a major influence in creating and maintaining these feedback loops. A huge influencing factor in most recommendation algorithms seems to be a “Other people who liked X also liked Y”. Whether it’s your Amazon recomemndations, Netflix recommendations, or presumably sorting of your YouTube, Facebook, or Twitter feeds, cross-user behavior seems to be a strong component of how recommendations systems are crafted and influenced (much stronger than any actual content classification).
The problem with this for the purposes of this discussion is that people, frankly, suck. As Facebook called out, there tends to be more engagement as content approaches the boundaries of acceptable on a platform – despite people making the claim that they believe this content harms the platform, there is still a consistent increase in engagement as content becomes more extreme on some axes. These choices by users then end up influencing algorithms to expand the circles of folks exposed to that content, giving rise to the underlying radicalization components. In social situations, people tell people about the thing that sticks out in their mind the most – and there’s no difference in the consumption of online content, where the most unusual or extreme content tends to get more attention because it is simply more effective at capturing the minds of those consuming it.
This is clearly visible without the direct influence of algorithms: we all tend to engage more with the things we feel most strongly about, in either direction. The concept of “hate-reading” dates back to at least 2012, reading something because it’s just so bad that you can’t look away. (The recent Sunday Times piece focusing on lifestyle habits of people partaking of products like the HumanCharger, charcoal cleanses and sun staring fit this bucket for me, for example.) This habit is well ingrained in our overall media consumption habits, and it is exploited by everyone from CNN to the latest YouTube influencer to make the news.
As a result of this tendency to engage with the most extreme forms of anything, there’s a feedback cycle, even when divorced from algorithmic expression. For example, it is clear that many of our news networks have fallen into the trap of reporting on the most sensational bits of information, clickbaiting via social media platforms, their teaser trailers for upcoming segments, or even their chyrons, but it’s not just that the algorithms show this content to more folks: it’s that the clickthrough rates on this content are simply higher.
For YouTube in particular, this has a special significance because many of the top creators are compensated directly in line with their performance on the platform. With an incentive to create content which reaches the broadest audience possible, there is a reinforcement system in place that rewards those who create more “sharable” content: to create content which attracts the attention of more consumers. This means that even if you wanted to give equal share to both halves of the previously described bell curve, the content library likely simply doesn’t support it: well-produced content will tend to lean more heavily towards one side of the curve than the other: more extreme content will tend to be viewed more often and shared more often, so there is a greater incentive to create that content, creating a gap of less extreme content. (The same systems of feedback also apply to other platforms – whether it’s freelance writers or simply news networks as a whole – but the effects tend to be both less immediate and more diffuse.) Even completely divorced from algorithmic influence, the tendency of people to engage more with the most extreme form of whatever they’re consuming – combined with a global, instantaneous social communication network – would likely produce a more muted version of the same results.
In the Public Knowledge post, Ms. Lee writes “This dynamic should not be confused with users intentionally selecting certain content, like a decision to read only right-wing or left-wing news sites.” I think that the simplicity of this statement may miss the massive level to which all of the algorithmic ills we like to attribute are heavily influenced by those intentional selections in the first place, and this concept may be much more difficult to separate than is imagined.
The Sociopolitical Landscape
Unfortunately, the bad faith efforts of a number of politicians to impugn the political neutrality of our existing social media platforms has created an environment that hamstrings efforts to invest more heavily in correcting the biases in our systems. With regulators routinely opining that political bias exists where there is none, the looming threat of regulation could remove the existing ability of platforms to perform even the relatively moderate influencing that they attmept today to mitigate the effects of extremism.
In 2016, Facebook was accused of bias for using humans to write descriptions of its trending topics. In the end, those claims of bias were completely overblown in media reports: the reality is that Facebook had a neutral set of guidelines that were helping its editors to achieve a task which computers were simply incapable of doing well enough to be sufficient. However, Facebook has not returned to using human editors for their trending topics, instead leaning heavily on “algorithms” in all of its modern marketing to politicians.
These choices are not being made for the technical reasons that many would seem to assume, or even because of the more straightforward cost-saving that would at least be understandable. Instead, “tech’s trying to beat meat brains at a task humans have difficulty with, on a two-year deadline, not because anyone believes this is a good idea, but because any other reform will be reversed.”
In the current landscape, tech is surrounded by potential missteps, with almost no direction it can walk in without smacking itself in the face.

Lean too heavily on algorithms, and the growing effects of the small portion of false positives at scale will continue to create anecdotes that influence the narrative far more than is deserved. Lean too heavily on human editorial decision-making and you’ll be accused of bias, and regulators will work to remove the only elements of control you can use to protect your platform and your users. In this situation, you’ll be left as a host to a variety of content that is far beyond the line of what is seen as objectionable on these platforms today. Especially given the underlying bias of the source of these claims that tech companies are misbheaving – where those seeking to attack the tech platforms the most tend to be coming from a position of extreme lean towards one political view – and you’ve created a disaster of epic proportions just waiting to happen.
In order for tech companies to make any forward progress, I think that the Sword of Damocles that is currently hanging over their heads would have to be removed. I see no way to achieve that goal, other than by regulation. It is difficult for me to imagine that regulation written while the sword hangs will be effective at achieving positive results. It is equally difficult for me to imagine tech companies making meaningful process on correcting anything but the most egregious elements of radicalization while it hangs.
The sociopolitical landscape that faces tech companies that just want to do the right thing is fraught with disaster in every direction, and it’s not clear to me what the hell can be done about that.
Where to Go Next
The Public Knowledge post that spawned this is an interesting piece to keep in mind for those building algorithmic engines that drive engagement, especially at our major media platforms. I hope that the suggestions it makes can be achieved in some way, because I do believe that a framework that achieved what it recommended could be effective at solving some problems with filter bubbles that our existing platforms have. Unfortunately, I believe that there are technical limitations that make the suggestions likely impossible to implement today; if the technical could be solved, I think that you’d still have a major problem of the social behavior of consumers replicating many of the underlying algorithmic effects; and even if these problems could be solved, the political landscape incentivizes companies to do as little as possible for fear of upsetting the careful balance they’ve been able to strike with regulators so far that prevents aggressive bad faith takeovers of the platforms.
In short: I just spent 2500 words telling you “I don’t have any clue what we can do. Let’s just give up and go back to stone tablets.”
All opinions are my own and not those of my employer.